#
Extracting Images
#
Arkose FunCAPTCHA
FunCAPTCHAs are composed of one image that is a collage of 6 images. The entire image is 300px by 200px, with inner images being 100px by 100px. FunCAPTCHA image source contains the image already encoded in base64, so all we need to do is to remove the tags in front of it to extract the image data.
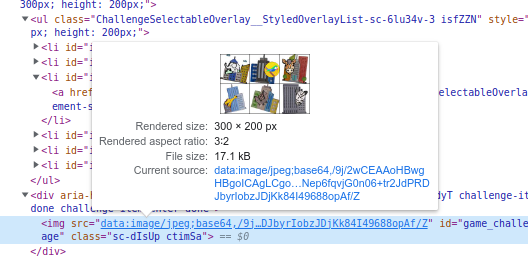

For FunCAPTCHA recognition, send the entire image in base64.
#
Google reCAPTCHA
Google reCAPTCHA is a bit tricky. Its puzzles can be divided into 3 categories: 4x4, 3x3-single, and 3x3-multiple. The source of all image elements are URL.
The 16 grid challenge is the easiest to extract because it is only one image of size 450px by 450px.
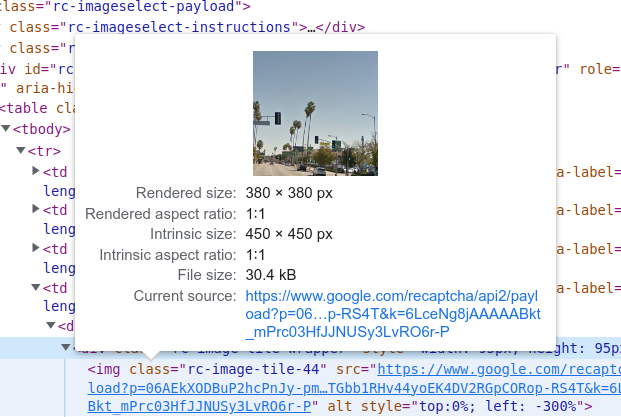
Despite belonging to the same image, each grid contains its own image element with the same source as the rest.
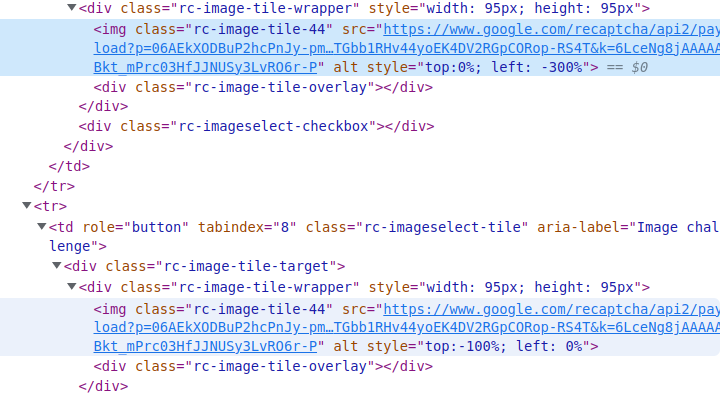
For 3x3 images, the first image that is rendered is always a collage of 9 images of size 300px by 300px. Similar to 4x4, each grid contains its own image, with all of them being idential.
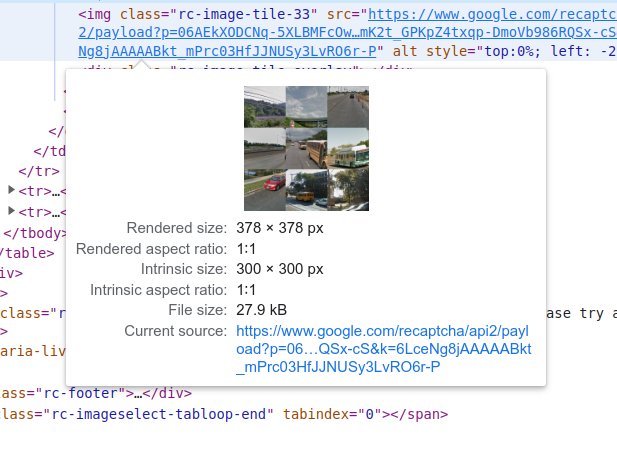
For 3x3 challenges where you must wait for more images to load, the freshly loaded images are 1x1 images of size 100px by 100px. For recognition, after submitting the 3x3 image, send only the 1x1 images when they appear.
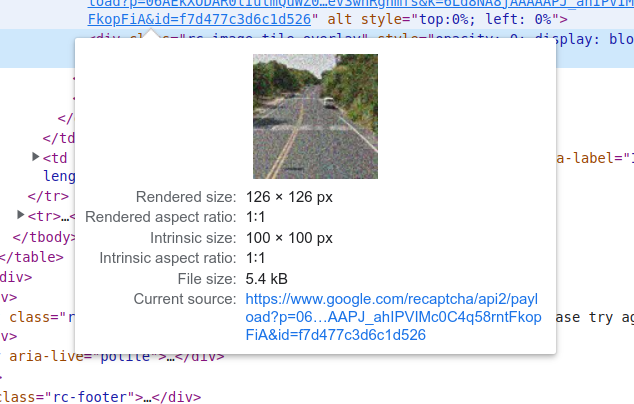
You do not need to convert the image URLs into base64 as our API allows you to send an array of image URLs.
#
hCaptcha
Unlike reCAPTCHA 3x3 images, each hCaptcha grid contains individual images. Their size varies, and the source is a URL image.
hCaptcha image URLs are not sources of image elements. They are embedded in the background style of a div element. As such, you need to select these div elements, get the background style, and parse the image URL through string slicing, replacement, or regex extraction.
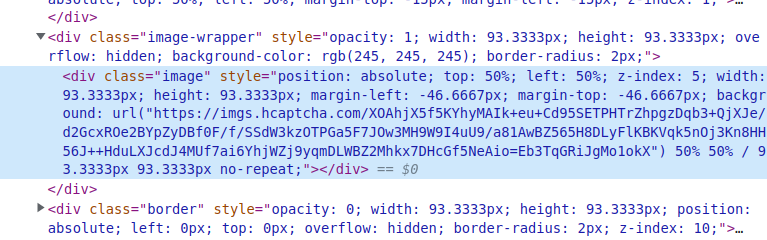
You do not need to convert the image URLs into base64 as our API allows you to send an array of image URLs.
#
Text CAPTCHA
Text CAPTCHAs are problematic because each CAPTCHA provider has its own way of serving images. There is no one-size-fits-all method to extract them.
A common mistake is sending transient image URLs to the Text CAPTCHA recognition API. Some CAPTCHA providers serve different images each time you request the image from a URL. If you send such image URLs to the API, our AI will see a different image than what you need to solve. As such, it is always safer to convert a Text CAPTCHA image URL into base64-encoded image before sending the challenge to the recognition API.
Converting a transient URL into base64 may be more difficult than one would expect. Typically, you would use a function such as the following to convert an image URL to a base64-encoded image:
function toDataURL(url, callback) {
const xhr = new XMLHttpRequest();
xhr.onload = () => {
const reader = new FileReader();
reader.onloadend = () => {
callback(reader.result);
};
reader.readAsDataURL(xhr.response);
};
xhr.open('GET', url);
xhr.responseType = 'blob';
xhr.send();
}However, this method requests the image from its source again, and if the image URL is transient, the returned base64-encoded image will be different from what you want to solve. To handle such cases, you need to use a canvas element, paste the existing image element onto the canvas, and convert the contents of the canvas to a base64-encoding.
const $canvas = document.createElement('canvas');
$canvas.width = $img.naturalWidth;
$canvas.height = $img.naturalHeight;
const ctx = $canvas.getContext('2d');
ctx.drawImage($img, 0, 0);
const b64_image = $canvas.toDataURL('image/jpeg').split(';base64,')[1];Note that this method will not work if the image is loaded from a different origin as modern browsers' security policy will not let you peek into what is rendered on another origin. To save ourselves from being tangled in an overly complex heist involving proxies and webrequests, we encourage you to use the browser API via tools such as Selenium to take a screenshot of the image element and save yourself the trouble.